Estimated total volume of Google searches
This project concerns the analysis of the total Google queries relating to the “Premier League” research carried out in the last 12 months in the United Kingdom in order to estimate the total volume. All the analysis carried out took place with the aid of the programming language R.
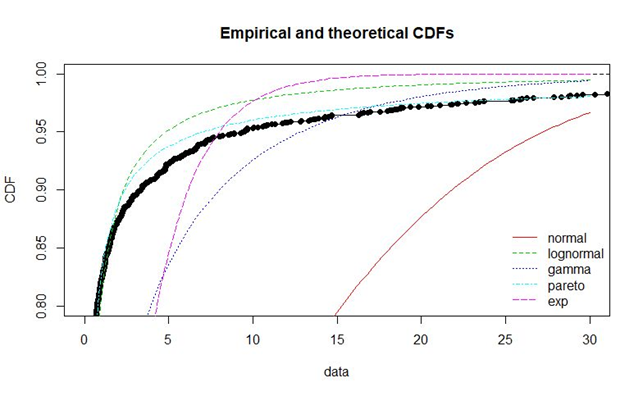
Once the data was collected, the dataset obtained was represented in such a way as to be able to evaluate its distribution and hypothesize a model that was congruent with the empirical trend of the data, using the Q-Q plot or the Shapiro-Wilk test, which excluded a normal distribution.
Then the power-law, log-normal and exponential distributions were investigated, using the log-Maximum Likelihood Estimation, thus estimating the various parameters.
Finally, using the Kolmogorov-Smirnov distance it was obtained that the distribution that best fits the data is the log-normal.
Further analyzes were carried out to obtain the best parameters for the distribution, then the number of searches and the volume of searches were estimated using defined estimators.
Download of the document
If you want to know more, get more details, also from a statistical point of view regarding the procedures used, I invite you to download the report below (only italian).