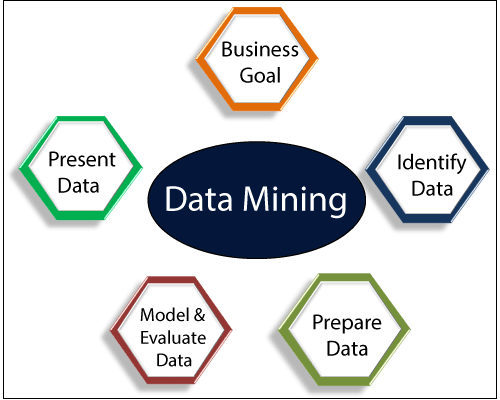
This is the first ever project related to data mining or machine learning. The dataset used was Carvana, a company that deals with the resale of used vehicles in the United States.
Then exploratory analyzes of the dataset, data cleaning and data preparation were carried out.
Several clustering algorithms have been applied, such as K-means, DBSCAN and hierarchical clustering.
We analyze the main association rules that can be identified within the dataset and their applications for determining and replacing Missing Values and in the classification of the target attribute of the analysis.
Finally, classification algorithms were applied, such as Decision Tree, Random Forest, KNN, followed by an interpretation of the results obtained.
Download of the document
If you want to have information and details on the tests performed with the different algorithms, download the document below (only Italian).